Six Sigma Alarm Management Part 2

By Brent J. Thomas
In our last issue (Sigma Alarm Management), we covered how the Soda Springs team defined and began to measure its alarm problems using Six Sigmas define-measure-analyze-improve-control (DMAIC) process. In this article, we see how, after further measurement, the team moved on to the last three steps.
One of first conclusions we reached in our measurement process was that the present alarm management system needed to be upgraded. LogMate, from TiPS, had been in use since 1992, but was little more than an event historian. It wasnt compatible with DeltaV from Emerson Process Management or the new DeltaV Operate for PRoVOX (DVOP) consoles that were in development.
A new network-based version of LogMate compatible with PRoVOX, DVOP, and DeltaV was available. The new version also possessed considerable analysis capability and the ability to document and manage the alarm configuration in the control system.
Using Alarm Configuration Expert (ACE), the first thing we discovered was that we had an enormous number of integrity errors. Integrity errors occur whenever a machine loses contact with the network. The old LogMate wasnt network-based, so it couldnt see network errors. We knew the errors were there, but had no idea how bad they were, and we had no reliable way to measure them.
These errors dont produce an audible alarm, so generally they dont contribute to operator loading. If there are enough of them, however, they do affect the operators by turning their DVOP displays magenta, which is DVOPs way of telling the operator that the data on the screen isnt current. Besides being annoying, this leaves the operator with no window to the process and no way to control it. If it lasts more than a few seconds, it can be very serious.
So, the integrity errors would have to be addressed by another group separately from the alarm management effort. For further measurement and analysis of the audible alarms, these errors were filtered out of the alarm data, and handled separately.
The Baddest Actors
With the integrity errors removed, the worst players in the alarm system became apparent. It was expected that the furnace pressure alarm, PC936-1, would be the worst, but not as bad as it turned out to be. This one was clearly an outlier that overwhelmed the rest of the data. The CO Main temperature was the next most common, followed by the PRV inlet pressure. It was also immediately apparent that the furnace on/off alarm had been duplicated.
Its sometimes necessary for two PRoVOX controllers to get information from the same instrument. In this case, both the furnace controller and the stocking system controller needed the furnace on-off indication EI935-5. This is done in PRoVOX through virtual communication by building an identical point in the second controller. Since these reside in the same database, the names can be similar, but have to be slightly different, such as EI935-5 in the F9 controller and EI935m-5 in the stocking system controller. Unfortunately, both points were mistakenly given alarms.
DeltaV handles multiple-device communication in a way that doesnt require a duplicate point. Therefore, this type of duplication of alarms will be eliminated when the entire control system is converted to DeltaV.
In addition to measuring how many times each alarm activates, we can look at how the alarms relate to each other by running a related analysis. This table says the pressure control deviation alarm, PC936-1::A, activated 83 times during the time period. Of those 83 times, the furnace pressure high alarm, PC936-1::C, activated 61 times. This told us that we should separate the two furnace pressure alarms because each is a significant contributor to the total alarms by itself.
The Analysis Phase
For the analysis phase, the same components are used with the addition of ACE. The data was exported and some of the analysis done using Minitab.
Samples taken at smaller intervals were auto-correlated, which makes perfect sense. In the event of a process upset, it stands to reason that the number of alarms in one short period of time will have an effect on the number that occur in the next period. We found that if we measured the data in four-hour periods, we could eliminate auto-correlation.
The process capability analysis shows a lot of opportunity for improvement.
The Improve Phase
The components used in the Improve phase are ACE and the Alarm knowledge base (KB). ACE is used to pick out the bad actors or low-hanging fruit. The team decided to concentrate on 10 at a time: rationalize the worst 10 alarms first, then the next 10, and so on.
Each alarm was discussed at each meeting until all concerns about any changes were answered. The first management of change (MOC) was approved in July 2006, and changes were made in August 2006.
With integrity errors, the mean was reduced by 86%, StDev (within) by 93%, and StDev (overall) by 95%. Eighteen percent of the samples were outside the upper control limit in March, and none in August. For audible alarms the mean was reduced by 61%, StDev (within) by 45%, and StDev (overall) by 44%. (See Figure 1.)
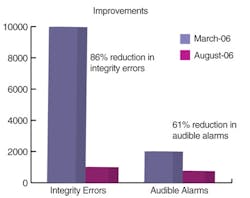
Figure 1. Six-month improvement in integrity errors and audible alarms.
T-Tests and ANOVA from Mini-Tab demonstrated that the data showed significant improvement.
The Control Phase of DMAIC
Long-term control of the alarms will be achieved using the following strategy. The alarm management steering team (AMST) completed a comprehensive alarm philosophy. It also established an alarm knowledge base that includes configuration for DCS alarms, locations and access of hardwired alarms, automatic nightly updates from DeltaV, and it has developed a management of change approval system.
The AMST is making progress on defining actions for each audible alarm. Theres still some debate as to how valuable this is compared to the cost. We may do the most critical alarms, but not all of them. Its also been decided that the DCS group will be responsible for maintaining the tools, and the engineering and manufacturing departments will ensure adherence to policies and philosophy.
The same alarm management procedures were conducted for the other two furnaces in 2007. The overall results were essentially the same as the first furnace.
By pursuing the big hitters revealed by LogMate, Monsanto was able to reduce alarm activations in the furnace area of the Soda Springs, Idaho, plant. Overall operator loading was reduced by 62% when alarms on all three furnaces were rationalized. (See Figure 2.)
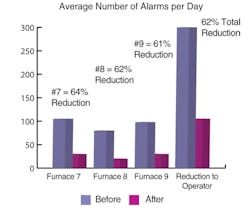
Figure 2. The results of the DMAIC approach over three furnaces.
Monsanto, Soda Springs, isnt yet finished with its overall alarm management project. The AlarmKB will be used to catalog the most critical alarms in the plant with fields for probable cause, confirmation, consequence, corrective action, test requirements and reliability tracking. The operator can reach this display by clicking on a link provided in NetView. Changes to the alarm system are first put into a pending table, and must be approved before theyre reflected in the knowledge base. The production engineer is notified of all changes regardless of alarm priority. Changes to critical alarms can trigger additional notifications. Rights and privileges are managed and maintained at the control system level.
Brent J. Thomas is a manufacturing technologist at Monsanto.

- read our article Six Sigma Alarm Management.
